以前はSPSSやSAS等の大規模で高価な統計解析ソフトで処理した論文でないと、統計解析結果をEditorが承諾しないという暗黒の時代がありました。最近はRで解析したものもAcceptされるようになりました。統計の授業でもRの使い方を教えてますからね。是非皆さんも、Rを使ってみてください。
S言語とR言語について
統計解析ソフトRは、S言語と呼ばれる、統計解析専用のプログラミング言語をモチーフに開発されたオープンソースソフトウェアOSSです。S言語は、1984年、AT&Tベル研究所の John Chambers, Rick Becker, Allan Wilks らによって研究・開発された統計処理システム(Sシステム)用の言語で、1988年にプログラミング言語としてS言語の仕様が策定されました。
R言語は、GNUプロジェクトによりオープンソースで作成されたもので、S言語の文法を取り入れており、現在はS言語よりも多くの機能(ライブラリ)を有しています。R言語を最初に実装したのはニュージーランドのオークランド大学のRoss Ihaka先生とRobert Clifford Gentleman先生です。現在ではR Development Core Teamによりメンテナンスと拡張がなされています。
Rをダウンロードしてインストールしよう
Rは自由ソフトです。誰でも自由に使え、制限はありません。Rシステム及びライブラリはCRANと呼ばれるサイトで管理されており、世界中にCRANのミラーサイトが存在します。日本のCRANミラーサイトは山形大学のようですね。(CRANサイトは不定期に変更されます。)
各自のパソコンOS用のRをダウンロードしてください。インストールはいたって簡単ですが、Windows版の場合は、一か所だけ気を付けて欲しいです。標準ではインストール先のフォルダが「C:\Program Files\R」になりますが、後々面倒なことになるので、「C:\R\R-(バージョン番号)」もしくは「C:\R」のように、スペースが入らないものに変えてください。
インストールが完了したら、早速、起動してみましょう!
「ほえ?コンソール?」 そうなんです。ここにコマンドを打っていくんです。
そこの貴方!「めんどくさい! SPSSやExcelが良い」なんて思ったんじゃない? 違うんですよね~! コンソールコマンドはコピペ出来るんです。断然こちらが楽ですよ!!
まずはR言語の基本を、ほんの少しだけ説明します。
ネットでググれば、幾らでも使用例がありますが、ここでは最小限知っておいてほしい事のみ記載します。
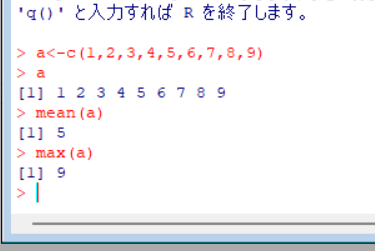
まず、データの塊のことをRではベクトルと呼びます。ベクトル「a」を作ってみましょう。以下の赤字の部分をコピペしてください。
「<-」は、ベクトルをコピーします。c(数値,数値,数値,数値)は、ベクトルの表現型です。
ベクトル名だけ入力すると、その中身を見ることができます。
mean(ベクトル名)は、平均値を計算して返す関数です。 max(ベクトル名)は、最大値を返す関数です。
a<-c(1,2,3,4,5,6,7,8,9)
a
[1] 1 2 3 4 5 6 7 8 9
mean(a)
[1] 5
max(a)
[1] 9実際に実行したら、こんな画面になります。aというベクトルを定義して、その平均値と最大値を表示したわけです。
(まだツマラナイですよね。これからが本番ですよ!)
日本の統計情報をメタ分析してみよう!
総務省統計局は、日本の統計情報をExcelファイル等で公開しています。今回はそのデータを元に、2023年の5歳~17歳の児童の身長と体重のデータを作成しました。公開された統計情報を元に分析可能なデータを作成して、複数の研究論文を再分析して評価することを「メタ分析」と呼びます。(メタ分析用データの具体的な作り方は、Perl言語の解説ページでソースも公開してます。)
Windowsの方は、ドライブCに「data」というフォルダを作成してください。そこに、以下のcsvファイルをダウンロードして格納してください。以下の説明は、絶対パスが「C:\data\e-stat_hw_2023.csv」となっていることが前提になっています。バックスラッシュは半角の「¥」と同じです。
R言語でよく使うライブラリをInstallする
以下のコマンドを入力してください。もしくは、GUIの「パッケージ」→「パッケージの読み込み」から選んでも良いですが、凄まじい量のパッケージがあるので、コピペが断然楽ですよ! 以下に限っては、一行ずつコンソールにコピペしてください。
install.packages("summarytools")
install.packages("ggplot2")
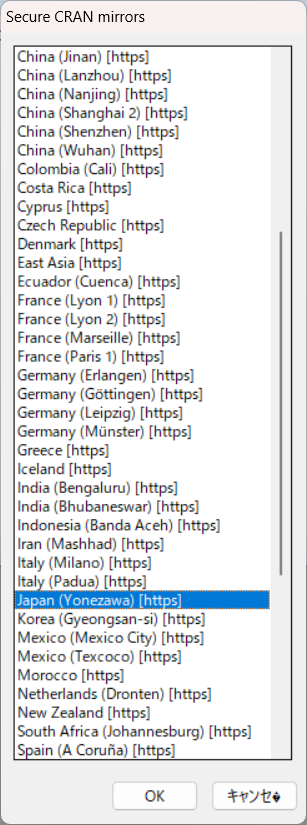
始めてパッケージをインストールする際には、CRANミラーサイトを選ぶ画面が出てきます。特に拘りが無ければ、日本のサイトを選びましょう。
csvデータを読み込む
以下のコマンドを順番にコピペして、先程ダウンロードしておいた「C:\data\e-stat_hw_2023.csv」ファイルを読みこみます。
具体的には、ライブラリを有効化し、データ格納フォルダを「c:\data」と設定して、dfというベクトルにcsvデータを読み込んでます。ついでにデータのサマリも作成しています。
library(summarytools)
library(ggplot2)
setwd("c:/data")
df <- read.csv("e-stat_hw_2023.csv",header=TRUE)
view(dfSummary(df))突然、ブラウザが開いて、以下のような画面が開くと思います。(何らかのエラーが表示されたら、Rを閉じて、パッケージのインストールからやり直してみてください。)26万4534件のデータが含まれています。ある程度メモリが無いと動かないかも。
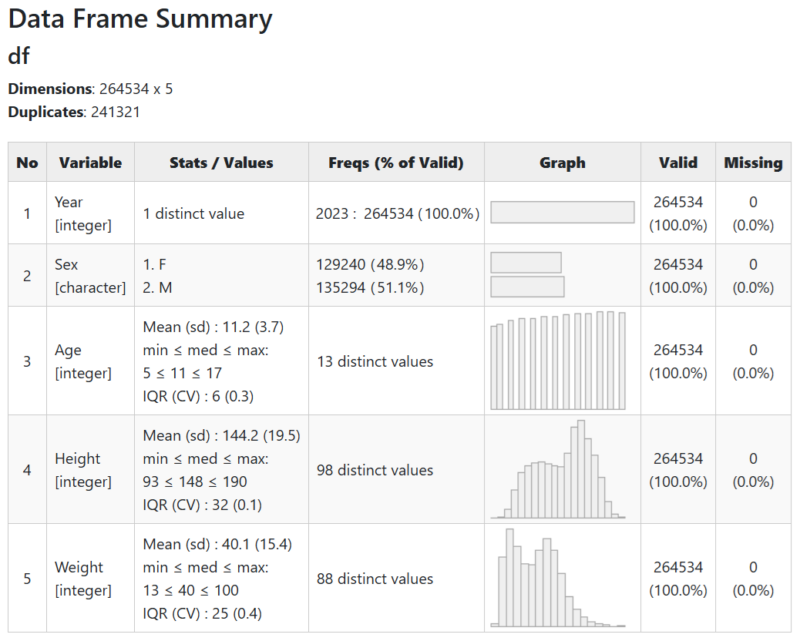
身長と体重が、正規分布してないですよね。これは5歳~17歳の男女のデータが混在しているからなんです。
15歳の男女の身長のヒストグラムを描く
ここで15歳のデータに絞って、身長のヒストグラムを作成してみましょう。以下のコマンド(赤字)を全てコピペしましょう。
最後の1行を入力するために、コピペした後にEnterキーを押す必要があります。
このように、#以下は、コメントが記入できます。 日本語も使えます。
df.15 <- df[df$Age==15,] # 15歳のデータだけに絞る。「df.15」という名前のベクトルに、Ageが15のデータのみ格納
#性別で色分けしてヒストグラムを描く
ggplot(data=df.15)+ # データフレームの指定「df.15」
geom_histogram( aes(x=Height, # ヒストグラムで、描画の対象となる変数xは、身長
fill=Sex), # 塗り分けの対象となる変数は、性別
position="identity", # 重ねて描くという指定
alpha=0.5, # 透明度の指定(重ねて描くので半透明にしている)
binwidth=3 ) # ヒストグラムの幅 3cm単位
「df.15」というのは、単に分かりやすい名前を付けただけです。「a」「b」のような名前でも構いません。
「df」というベクトルに約26万件のデータが入ってます。
「df.15」という名前のベクトルに、df の中から、Age==15のデータの、全ての行を格納しています。
「<-」これは、データをベクトルに格納するという意味
「df[条件,]」これは「条件に合ったレコード全て」という意味です。条件の後の「,」コンマには「全ての行」という意味があります。
条件は 「df$Age==15」ですね。ベクトル名$カラム名 という書式になります。この書き方はかなり面倒ですけど、慣れるしかない。
ggplotという関数がグラフを書くライブラリ関数です。詳しくはコメントを見てください。詳しい使い方は「統計 R ggplot ヒストグラム」等のキーワードで、ググってみてね。
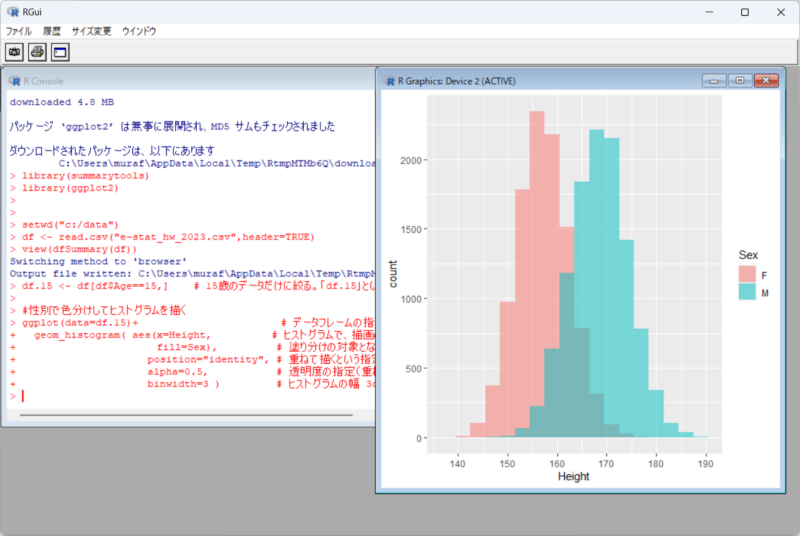
このような綺麗なヒストグラムが出てきましたか? 15歳だと、男性と女性の身長の分布には明らかに差がありそうですよね。後で有意な差があるのか、検定してみましょう。
男性と女性の身長差は、幾つぐらいから発生するのか?
年齢を横軸、身長を縦軸、性別を色分けした散布図を作成してみましょう。
df2023 <- df[,2:4] # 1列目の2023と5列目の体重は邪魔なので、2~4列目のみ含むベクトルを作成
ggplot(data = df2023,
mapping = aes(x=Age,y=Height,colour=Sex,shape=Sex)) +
### グラフの種類
geom_point(size=5,alpha=0.3) + # 散布図を指定
### 体裁
xlab("年齢") +
ylab("身長") +
ggtitle("2023年の性別・年齢・身長散布図")今度は、「df2023」というベクトルを作成しています。「df」の2~4列目だけ採用しています。今度はコンマが条件の前にあります。コンマの後ろに、必要とする列を列挙します。
散布図では24万個のデータを全てプロットするので、結構時間がかかります。ご注意ください。メモリが少ないパソコンでは無理かもです。
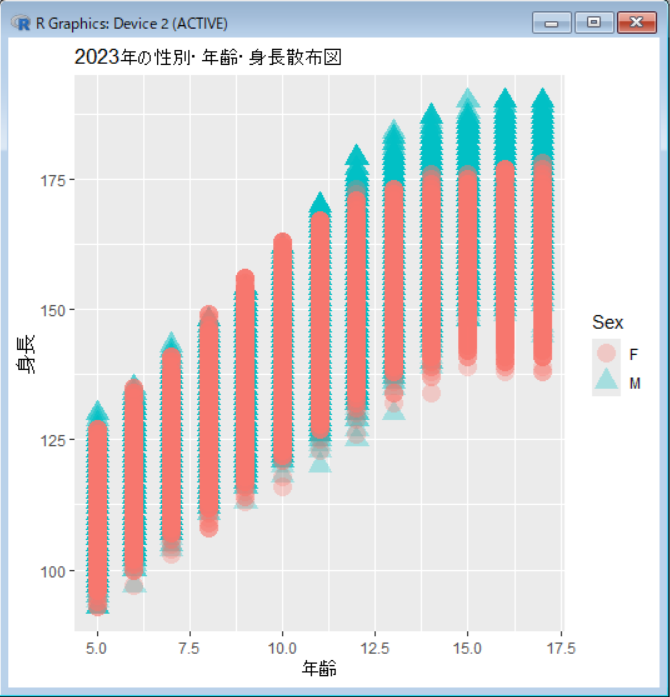
5歳では、ちょっと男の子が大きいかな。10歳で先に女の子の身長が伸び始めますが、12歳ぐらいから男の子がグングン伸びてますよね。
2群の差の検定(Unpaired T Test)を行ってみる
実は、今回のデータセットは膨大すぎて、かなり小さな差でも全て有意になってしまいます。(試してみたら分かります)
それでは面白くないので、サンプル数を300個くらいに無作為抽出してから統計処理してみましょう。
無作為抽出するために必要なライブラリがあります。先にそれをInstallしましょう。
install.packages("dplyr")
library(dplyr)8歳の男女300人のデータを無作為抽出して、ヒストグラムを描く
「dplyr」ライブラリを有効化すると、sample_n()関数でsizeを指定してデータ数をランダムサンプリングできます。ランダムサンプリングは、実行するたびにデータが変化し、ヒストグラムの形が変わります。同じ実験を何度も繰り返すと、得られるデータが変化する様を観察できますね!
df.8.s300 <- sample_n(tbl = df[df$Age==8,] , size = 300) # 8歳のデータから300例をランダムサンプリングする
ggplot(data = df.8.s300)+ #データフレームの指定
geom_histogram( aes(x=Height, # 描画の対象となる変数
fill=Sex), # 塗り分けの対象となる変数
position="identity", # 重ねて描くという指定
alpha=0.5, # 透明度の指定
binwidth=3 ) # 3cm幅にする
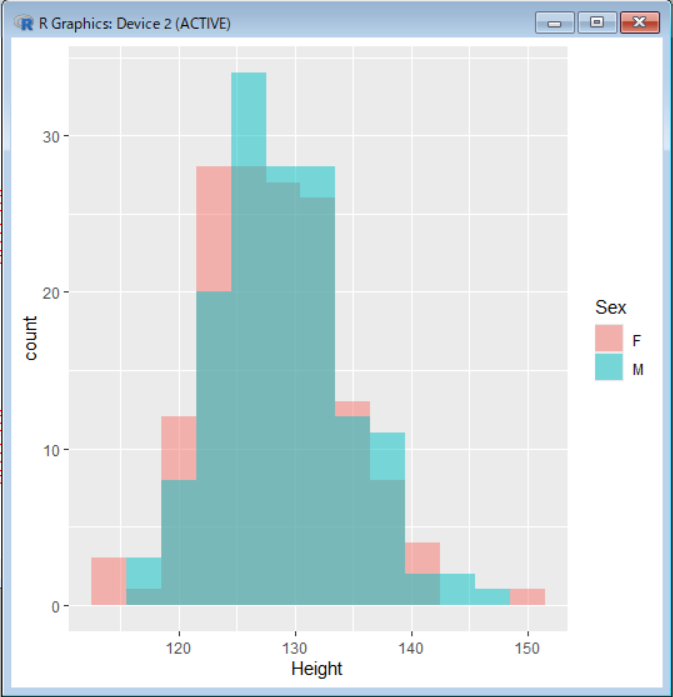
如何にも差がなさそうな感じですよね。
繰り返しになりますが、「df.8.s300」は、単なるベクトルの名前です。「b」でも同じです。以下の例を参照してください。
b <- sample_n(tbl = df[df$Age==8,] , size = 300)
ggplot(data = b)+ #データフレームの指定
geom_histogram( aes(x=Height, # 描画の対象となる変数
fill=Sex), # 塗り分けの対象となる変数
position="identity", # 重ねて描くという指定
alpha=0.5, # 透明度の指定
binwidth=3 ) # 3cm幅にするベクトル名がbでも動きます。でも、「b」って何だっけ?ってなりますよね。だから僕は分かりやすい名前にしてます。
無作為抽出した8歳の男女300人のデータで、男女の身長差が有意であるか T TESTを行う
まずは、男の身長データと、女の身長データの、2つのベクトルを作る必要があります。身長以外のデータが入っているとダメなので、下記のコマンドで2つのデータを作ります。それをTTEST関数で処理します。
df.8.s300.m.Height <- df.8.s300[df.8.s300$Sex=="M",4] # 無作為抽出した8歳のデータで、性別が男で、身長は4列め
df.8.s300.f.Height <- df.8.s300[df.8.s300$Sex=="F",4] # 無作為抽出した8歳のデータで、性別が女で、身長は4列め
t.test (x=df.8.s300.m.Height, y=df.8.s300.f.Height, paired=F) # 対応のないT検定
Welch Two Sample t-test
data: df.8.s300.m.Height and df.8.s300.f.Height
t = 1.1649, df = 297.99, p-value = 0.245
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.5377192 2.0977886
sample estimates:
mean of x mean of y
128.8926 128.1126 300個のランダムサンプリングデータでは、8歳の男女の身長差には有意な差が無い(p=0.245 > 0.05)ですね。
最近のRでは、等分散しているであろうデータでもWelchで計算するようです。
15歳の男女300人の無作為抽出データを作成して分析する
df.15.s300 <- sample_n(tbl = df[df$Age==15,] , size = 300) # 15歳の男女300人のランダムサンプリング
ggplot(data = df.15.s300)+ # データフレームの指定
geom_histogram( aes(x=Height, # 描画の対象となる変数
fill=Sex), # 塗り分けの対象となる変数
position="identity", # 重ねて描くという指定
alpha=0.5, # 透明度の指定
binwidth=3 ) # ヒストグラムの幅3cm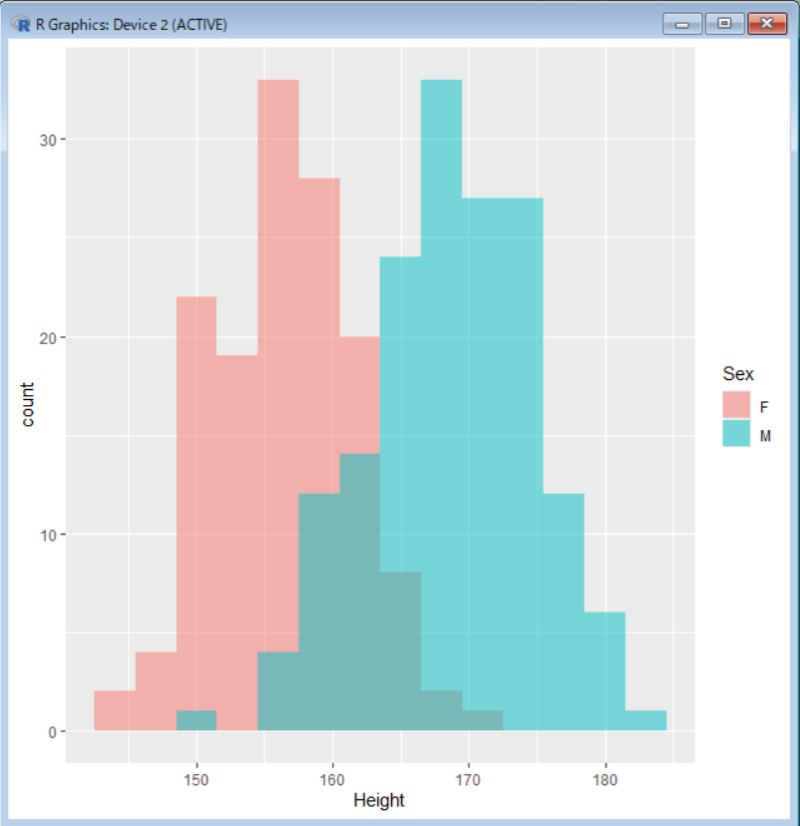
さすがにこれは計算するまでもないですが、一応、やってみましょう。
df.15.s300.m.Height <- df.15.s300[df.15.s300$Sex=="M",4]
df.15.s300.f.Height <- df.15.s300[df.15.s300$Sex=="F",4]
t.test (x=df.15.s300.m.Height, y=df.15.s300.f.Height, paired=F)
Welch Two Sample t-test
data: df.15.s300.m.Height and df.15.s300.f.Height
t = 19.144, df = 298, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
10.90237 13.40068
sample estimates:
mean of x mean of y
168.6335 156.4820 とてつもない小さなp値になりましたね。(p-value < 2.2x10-16)
サンプル数を小さくすると、何度かランダムサンプリングしているうちに、有意にならない値が出ることがあります。
また、10歳だと、女の子の方が平均値が大きいです。400例ぐらいあると、ほぼ有意になります。
色々試してみてください。